Best practices for data modeling in Hailer. Check this out before configuring complex structures.
Introduction
When modelling a set of processes in Hailer, a good approach is generally to first identify the central different objects, i.e. tables and what their relationships are. In many cases, there might be old software to be replaced or a set of spreadsheets that describe the current state. If not, the same information can usually be extracted through a set of interviews with the customer. Through this process, it is possible to identify the actual tables, their relationships and eventually their fields.
Getting started
It is usually a good idea to start with drawing a sketch of what the workspace will look like, e.g. using a tool like draw.io. Instead of trying to define what fields should be in which table or what phases workflows should contain, it is usually a good idea to focus first on which tables are needed, the relationships between them and what the tables represent.
In Hailer, this means modelling everything as datasets with only one category to begin with and adding the activity link fields first to validate the relationships make sense, to get a structure in place. The initial sketch can then easily be compared with the automatically generated overview in our Birds Eye View. Figuring out which fields belong in which dataset is usually easier when there is a solid structure in place.
Although it might be tempting to start creating a document or spreadsheet with the different datasets and fields that they should contain, keep in mind that the Birds Eye View automatically produces this based on the configuration in Hailer, removing the need of having to maintain separate documentation.
A simple modeling example
Let’s take a simple example where customer wants to create a simple customer registry and keep track of products sold, producing invoices and packing lists based on sales orders. A simple way of modeling this is the following:
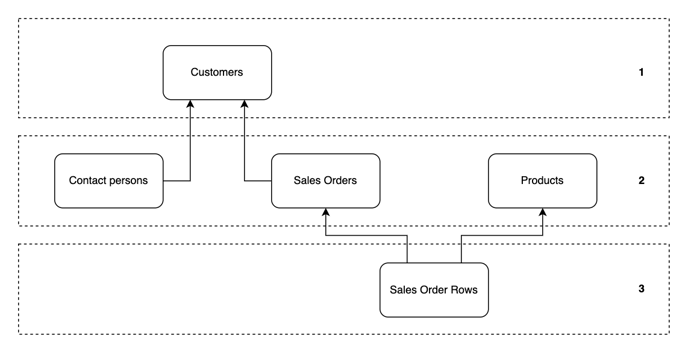
In this example, customers can have many contact persons and sales orders connected to them. A sales order can contain many sales order rows, while each row can refer to only one sales order and product simultaneously. Activity links usually point at table that is above itself in the data model hierarchy, which automatically creates an often logical hierachy in the data model (1, 2, 3).
A next good step is to then create datasets with the links needed, like in the picture below.
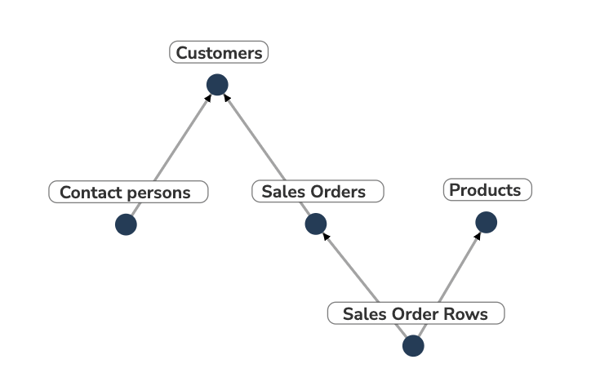
The Birds Eye View can then generate a picture of the data model in Hailer, which can be validated against the initial sketch.
Activity link direction
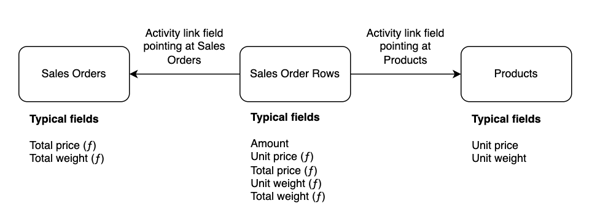
The direction of the arrow is essential, as it defines the type of relationship between the tables. An activity link is always a many-to-one relationship, while a many-to-many relationship needs an additional table. This is typically the hardest part to understand for new Hailer users, often leading to requests like having multiple choice in the activity link field. Another typical beginners mistake is to start creating activity link fields in the sales order and naming them product 1, product 2, product 3 etc. If you find yourself doing this, you are most likely not doing it right, as you are restricting the amount of products that can be part of a sales order and also not building a modular and flexible data model, but a hardcoded data model that is difficult to change later on. Therefore, a many-to-many relationship always requires a table that sits in between the two tables that should have a many-to-many relationship. A good example of this is having sales orders with sales order rows, pointing at a product dataset, like in the picture below.
For more in-depth information about activity links, check out the article Activity links in Hailer.
Adding phases and fields
When the initial structure is in place, adding the actual fields to be used is typically the next step. The fields needed vary a lot depending on the needs but in the picture above there are some examples of typical fields in this kind of setup. The table below is a list of all field types available in Hailer.
|
Field type |
Typical use case(s) |
Input example(s) |
|---|---|---|
|
Activity link |
Linking workflows and datasets together |
Company field in the Contact person dataset |
|
Text |
Short descriptions, phone numbers, product numbers, postal codes, names |
06100, +358401234567, Senior Developer |
|
Text Area |
Long descriptions, complete addresses, summaries |
Kirkkokatu 1, 06100 Porvoo, FINLAND |
|
Predefined options |
Different predefined statuses and categories |
Hotfix, Bug, Feature |
|
Numeric |
Price when currency is dynamic, different amounts |
1245, 34532 |
|
Numeric with unit |
Total weight, total price, license fee, total hours |
1 543 kg(s), 63 453 € |
|
Date |
Deadline, offer expiry date, release date |
14.11.2023 |
|
Date range |
Absence period, duration |
15.11.2023 - 18.11.2023 |
|
Time |
Event start when date is selected separately elsewhere |
14:50 |
|
Time range |
Event length when date is selected separately elsewhere |
14:50 - 15:50 |
|
Date & time |
Event start, various event timestamps |
14.11.2023 14:50 |
|
Date & time range |
Event duration, ticket resolve time |
15.11.2023 14:50 - 18.11.2023 15:50 |
|
Country |
Selecting country of customer or company |
Sweden, Marocko |
|
Team |
Selecting responsible team for project |
Sales Team, Project Team |
|
User |
Selecting responsible developer, project manager or sales person |
Mike Hampton, Sue Sullivan |
|
Linked activities |
Making input of sales order rows in a sales order easy and intuitive |
Sales order rows, Time tracking |
|
Subheader |
Separation between delivery address and invoicing address in a customer activity |
Invoicing details, Delivery details |
It is possible to choose on a phase and category level whether a field is visible or not. This allows enriching your data when proceeding with something in a workflow, like a sales case or development task. All fields can be set as required in a workflow or dataset, which means they are required when set visible in a particular category or phase.